Landslide susceptibility maps provide information on the spatial likelihood of landslide occurrence in a given geographical area. They are a precious tool for understanding landslide processes, estimating their impact on people and infrastructure, and planning mitigation countermeasures.
Landslide susceptibility has been the objective of countless studies, and many methods exist for generating susceptibility maps, mainly based on statistics or machine learning. Essentially, these models try to solve a classification problem: given a collection of spatial variables (and their combinations) associated with landslide presence or absence, a model is first trained to reproduce the observed outcome and then applied to unseen data to perform a prediction.
Contrary to many fields of science that use machine learning for specific tasks, no reference data exist to assess the performance of a given method for landslide susceptibility. A recent article published open-access in Earth-Science Reviews (
link) - led by Massimiliano Alvioli and coauthored by Marco Loche and Gianvito Scaringi from the Institute of Hydrogeology, Engineering Geology and Applied Geophysics - proposed a benchmark dataset serving this purpose. Using the dataset, the authors tried to answer two open questions in landslide research: (1) what effect does human variability have in creating susceptibility models? (2) how can a reproducible workflow be developed to allow meaningful model comparisons within the landslide susceptibility research community?
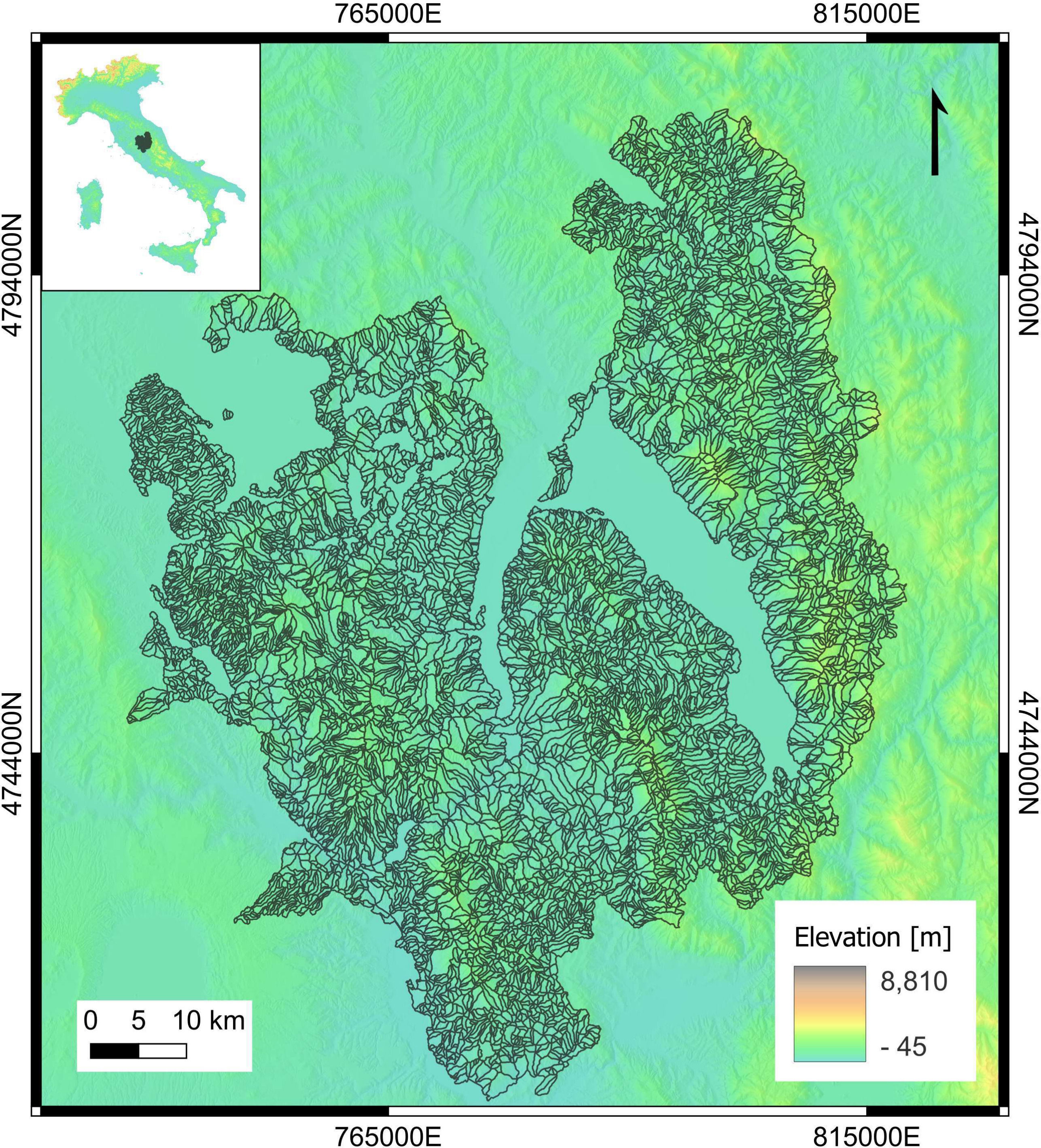
Figure 1. Geographical location (inset) of the area covered by the slope unit set (main figure) selected as a benchmark dataset for landslide susceptibility zonation. The dataset is a subset of the slope unit map obtained by Alvioli et al. (link) and used by Loche et al. (link) for a landslide susceptibility map of Italy. In the proposed benchmark dataset, point locations of translational landslides were chosen from the Italian national inventory known as ‘IFFI’ (Trigila et al., link).
With these questions in mind, the authors released a preliminary version of the dataset, along with a “call for collaboration,” aimed at collecting different calculations using the proposed data and leaving the freedom of implementation to the respondents. Contributions were different in many respects, including classification methods, use of predictors, implementation of training/validation, and performance assessment. That feedback suggested refining the initial dataset and constraining the implementation workflow. This resulted in a final benchmark dataset and landslide susceptibility maps obtained with many classification methods. The experiment did not intend to select the “best” method but only to establish a first benchmark dataset and workflow, that may be useful as a standard reference for calculations by other scholars. The experiment, to the authors' knowledge, was the first of its kind for landslide susceptibility modeling.

Figure 2. Boxplots of the distributions of susceptibility values in each model, obtained by assigning "presence" and "absence" attributes to slope units containing at least one landslide point or no landslide points at all, respectively. The box is around the region between the 1st and 3rd quartiles, the horizontal line is at the median value, whiskers extend to 1.5 times the interquartile range, and the points are outliers. Acronyms on the horizontal axis refer to the individual models, for which a legend can be found in Table 2 in the article (link).
The "call for collaboration" resulted in the organisation of a dedicated session, co-convened by Marco Loche, during the 2023 General Assembly of the European Geosciences Union. The session attracted 28 experts in landslide research from 20 different institutions in 12 countries. The article stemming from this collaboration describes results obtained independently by the authors using the benchmark dataset and aims to become a standard reference to comparatively assess the performance of independent methods for landslide susceptibility.
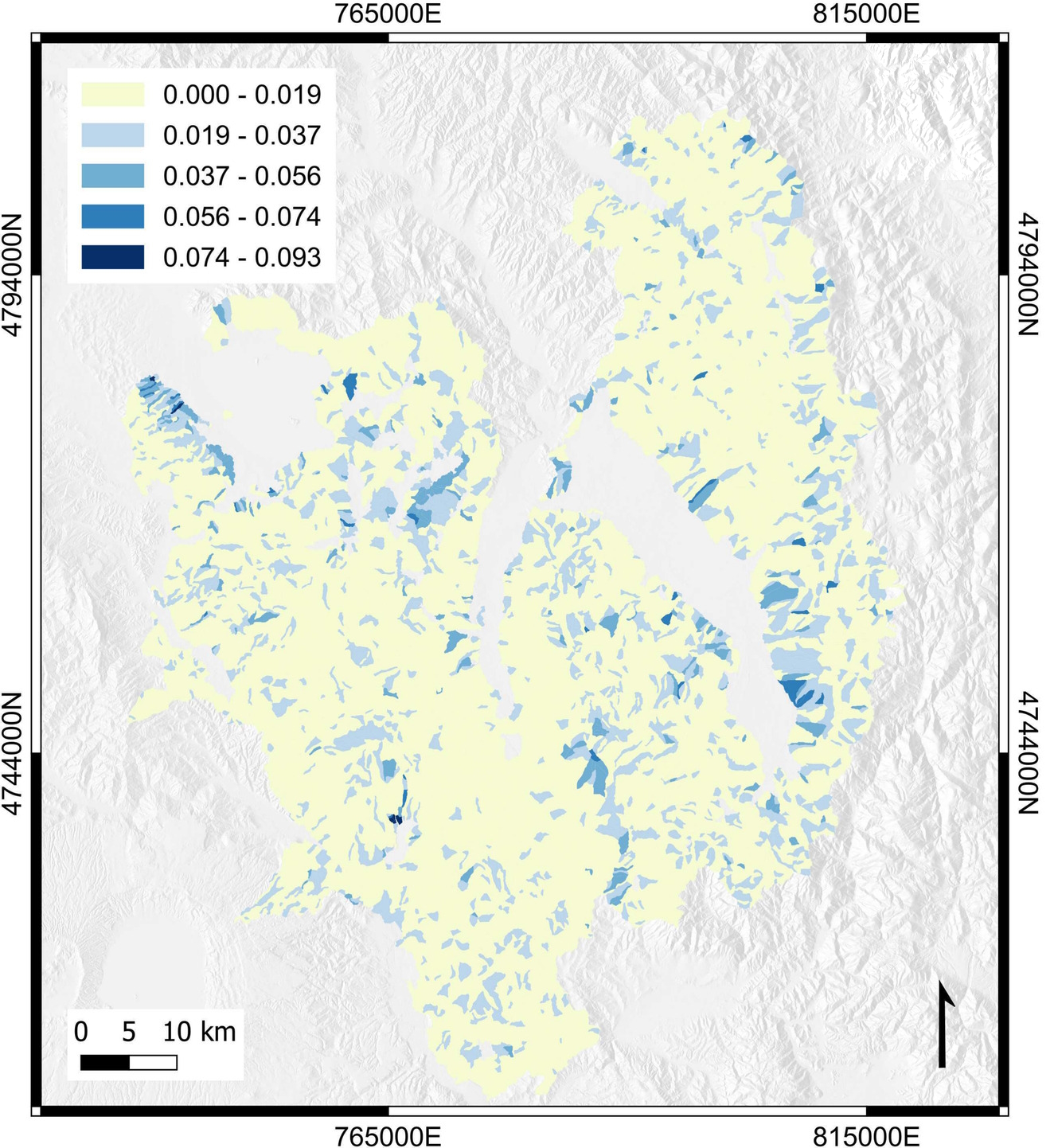
Figure 3. Variance of the susceptibility values in each slope unit, obtained with the proposed benchmark dataset for 16 different classification methods according to the landslide presence rule described in the caption of Fig. 2.




















